인터넷이 끊긴 순간 코딩 에이전트가 같이 끊겨버린 경험, 저는 꽤 여러 번 했습니다. 카페 와이파이가 불안정하거나, 비행기 안에서 갑자기 아이디어가 떠오르거나, 아니면 그냥 API 서버가 다운됐거나. 그럴 때마다 "이게 로컬에서 돌아가면 얼마나 좋을까" 싶었는데, 막상 시도해보면 속도가 너무 느려서 실용적이지 않았습니다.
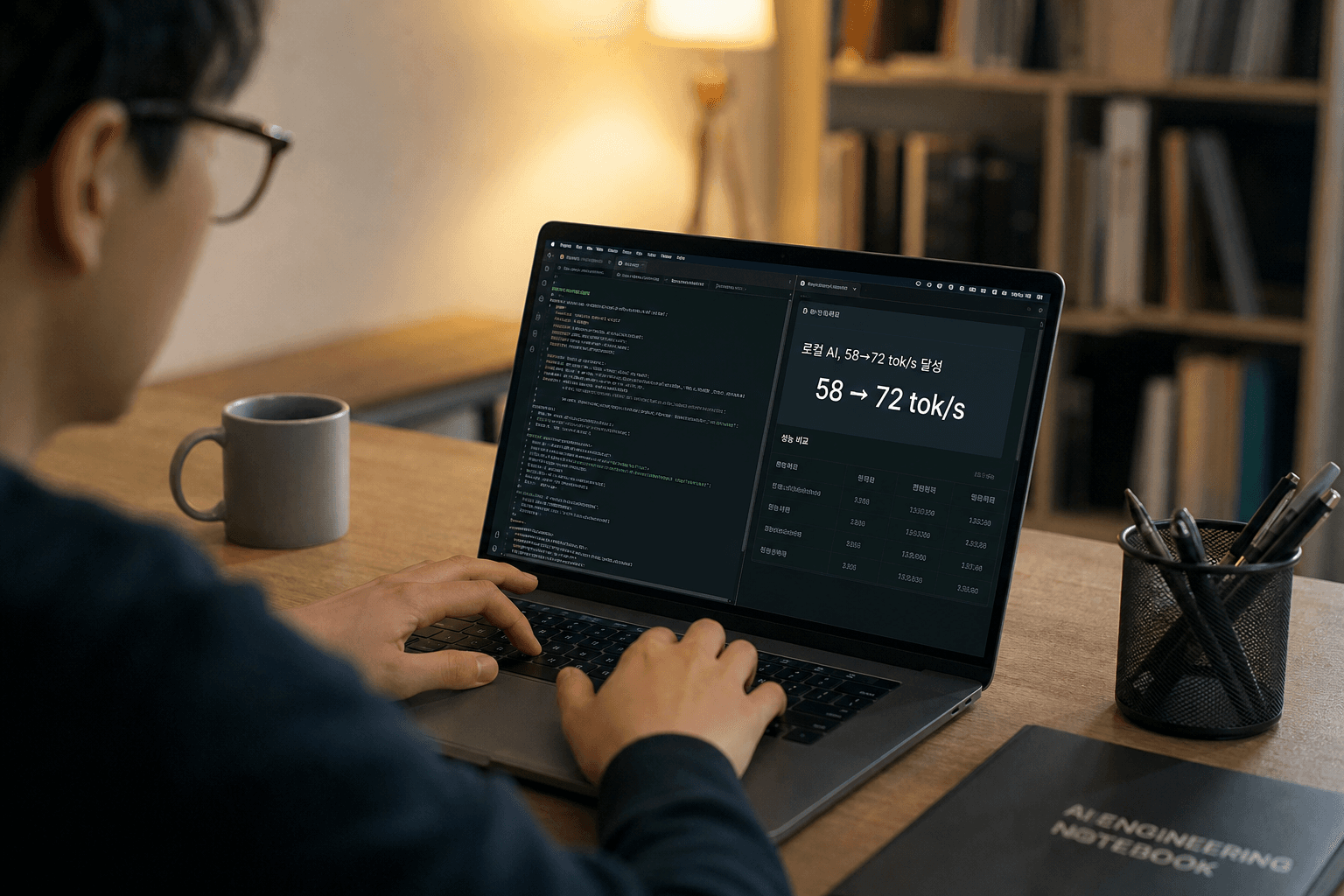
그런데 Gemma 4가 MTP(Multi-Token Prediction) 업데이트를 내놓으면서 상황이 달라졌습니다. MTP는 다음 토큰 하나만 예측하는 대신 여러 토큰을 동시에 추측해서 검증하는 방식인데 (쉽게 말하면 "다음 단어 하나씩 찍는 것"에서 "여러 단어를 한 번에 초안 잡고 맞는지 확인하는 것"으로 바뀐 것), 이게 실제로 꽤 의미 있는 속도 향상을 만들어냅니다. 이 글에서 다룰 최종 셋업을 기준으로 하면, Metal만 쓴 베이스라인이 58.2 tok/s였는데 MTP 드래프트 모델을 붙이고 나서 72.2 tok/s까지 올라갑니다. 약 24% 향상입니다.
완성된 셋업이 어떻게 구성되는지 미리 그려보면 이렇습니다. llama.cpp를 Metal + Accelerate로 직접 빌드해서 Mac의 GPU 가속을 최대한 끌어쓰고, 메인 모델로는 Gemma 4 26B-A4B를 Q4 양자화 GGUF 포맷으로 올립니다 (전체 모델 폴더가 약 17GB). 여기에 Q8 MTP 드래프트 헤드를 붙여 속도를 끌어올리고, 멀티모달 프로젝터도 함께 로드해서 스크린샷을 그대로 에이전트에게 넘길 수 있게 만듭니다. 에이전트는 Pi를 사용하는데, 이게 OpenAI 호환 API로 통신하기 때문에 나중에 다른 도구로 바꾸거나 추가하는 것도 어렵지 않습니다. 테스트 환경은 Apple M1 Max 64GB 통합 메모리, macOS 15.7.7이었고, 직접 녹화한 영상을 보면 에이전트가 실시간으로 충분히 쓸 만한 속도로 응답합니다.
흥미로운 점은 MLX가 Mac에 최적화된 프레임워크인데도 llama.cpp에 밀렸다는 사실입니다. 같은 4-bit 모델 기준으로 mlx-lm이 43~45 tok/s 수준인 반면 llama.cpp + Metal은 58 tok/s, MTP까지 더하면 72 tok/s입니다. "Mac에서는 MLX가 당연히 빠르겠지"라는 직관이 이 케이스에서는 틀렸습니다. 이 셋업을 처음부터 따라가려면 몇 가지 하드웨어·소프트웨어 조건이 맞아야 하는데, 그 체크리스트부터 정리해보겠습니다.
⚠️ 주의: MLX가 Apple Silicon 전용 프레임워크임에도 이 케이스에서는 llama.cpp에 밀렸습니다. "플랫폼 최적화 = 무조건 빠름"이라는 전제를 버리고 직접 수치를 재보는 것이 출발점입니다.

테스트 환경은 M1 Max + 64GB 통합 메모리였습니다. 이 조합이 기준점이라는 걸 먼저 짚어두면, 본인 장비와 비교하기가 편합니다.
메모리 기준부터 이야기하면, 최소 32GB는 있어야 합니다. 메인 모델(Q4_K_XL, 약 16GB) + MTP 드래프트 헤드 + 멀티모달 프로젝터 파일까지 합산하면 모델 폴더만 17GB를 넘습니다. 여기에 macOS와 에이전트 프로세스가 메모리를 나눠 쓰니, 16GB 장비에서는 페이지 아웃이 발생해서 속도가 처참해집니다. 저는 처음에 "어차피 양자화 모델이니까 괜찮겠지"라고 생각했다가 직접 겪고 나서 생각을 바꿨습니다. M2/M3/M4 칩이라면 같은 메모리 용량에서도 메모리 대역폭이 더 높아서 유리하지만, 핵심은 칩 세대보다 통합 메모리 용량입니다. Apple Silicon 이외의 환경(인텔 맥, NVIDIA GPU)은 이 가이드 범위 밖입니다.
소프트웨어 쪽은 세 가지만 챙기면 됩니다.
- Xcode Command Line Tools —
cmake와 C++ 컴파일러가 여기서 나오고,llama.cpp를 직접 빌드할 때 없으면 첫 단계부터 막힙니다.xcode-select --install한 줄이면 설치됩니다. - Homebrew —
cmake와tmux를 여기서 받습니다. 이미 설치돼 있는 분도brew update한 번 돌려두는 게 낫습니다. - Python 3.10 이상 — Pi 에이전트가 Python 환경에서 돌아가기 때문입니다. 시스템 기본 Python이 3.9 이하라면
pyenv로 올려두는 걸 권합니다.
macOS 15(Sequoia) 기준으로 작성했고, 14(Sonoma)에서도 동일하게 동작하는 걸 확인했습니다.
계정은 Hugging Face 하나만 있으면 됩니다. Gemma 4 모델 파일 세 개(메인 GGUF, MTP 드래프트, 멀티모달 프로젝터)가 모두 Hugging Face에 올라와 있고, Gemma 계열은 라이선스 동의가 필요합니다. 모델 페이지에서 "Access repository" 버튼을 클릭해 동의를 마쳐두지 않으면 다운로드 단계에서 403 에러가 납니다. 저도 한 번 겪었는데, 에러 메시지만 봐서는 원인을 바로 알기 어렵습니다. 계정 생성 후 huggingface-cli login으로 토큰을 로컬에 저장해두면 나중에 hf_transfer 가속 다운로드까지 그대로 쓸 수 있습니다. 디스크 여유 공간은 모델 폴더 17GB에 llama.cpp 빌드 아티팩트까지 더해서 25GB 이상 확보해두는 편이 안전합니다.
체크리스트가 다 갖춰졌다면, 이제 llama.cpp를 Metal과 Accelerate 프레임워크를 활성화한 상태로 직접 빌드하는 단계로 넘어갈 수 있습니다.

GitHub에서 llama.cpp 소스를 받아 직접 빌드하는 게 번거롭게 느껴질 수 있는데, 명령어 몇 줄로 끝납니다.
- 의존성 설치 — Homebrew가 설치돼 있다면 아래 한 줄이면 충분합니다. Xcode Command Line Tools는 체크리스트에서 이미 설치했을 테니, 이걸로 빌드 환경은 준비된 셈입니다.
brew install cmake
- 소스 클론 및 빌드 디렉터리 생성 — 소스를 받아서 빌드 디렉터리를 만듭니다.
git clone https://github.com/ggml-org/llama.cpp repos/llama.cpp
cd repos/llama.cpp
cmake -B build \
-DGGML_METAL=ON \
-DGGML_ACCELERATE=ON \
-DCMAKE_BUILD_TYPE=Release
cmake --build build --config Release -j$(sysctl -n hw.logicalcpu)
플래그가 두 개 들어가는 이유를 짚어두면 좋습니다. GGML_METAL=ON은 GPU 셰이더를 Metal API로 컴파일해서 M-시리즈 칩의 GPU 코어를 직접 쓰게 해주는 옵션이고, GGML_ACCELERATE=ON은 macOS 내장 BLAS(Basic Linear Algebra Subprograms) 라이브러리인 Accelerate 프레임워크를 활성화해 CPU 쪽 행렬 연산을 최적화합니다. 두 플래그를 함께 켜야 GPU와 CPU 양쪽을 제대로 활용할 수 있습니다. 한쪽만 켜면 생각보다 속도가 안 나오는 경우가 있어서, 처음 빌드할 때 빠뜨리기 쉬운 부분이기도 합니다.
-j$(sysctl -n hw.logicalcpu) 부분은 맥의 논리 코어 수를 자동으로 읽어서 병렬 빌드 스레드 수로 넣어주는 쉘 표현식입니다. M1 Max 기준 10코어라면 -j10과 동일한 효과가 납니다. 빌드 시간은 장비마다 다르지만 M1 Max에서 3~5분 내외였습니다.
- 빌드 결과 확인 — 빌드가 끝나면
repos/llama.cpp/build/bin/아래에llama-cli,llama-server등 실행 파일이 생깁니다. 제대로 됐는지 바로 확인해볼 수 있습니다.
repos/llama.cpp/build/bin/llama-cli --version
버전 문자열이 출력되면 빌드 성공입니다. 여기서 Metal이 실제로 붙었는지 확인하고 싶다면 --log-disable 없이 모델을 잠깐 실행해보면 로그에 ggml_metal_init 라인이 뜨는 걸 볼 수 있습니다. 빌드 자체는 금방 끝나지만, 이 단계에서 플래그 없이 빌드했다가 나중에 속도가 이상하다 싶어 다시 빌드하는 경우가 꽤 있어서 처음부터 확인해두는 편이 낫습니다.
빌드 바이너리가 준비됐으니, 이제 이 바이너리가 실제로 읽을 모델 파일 세 가지를 받아올 차례입니다.
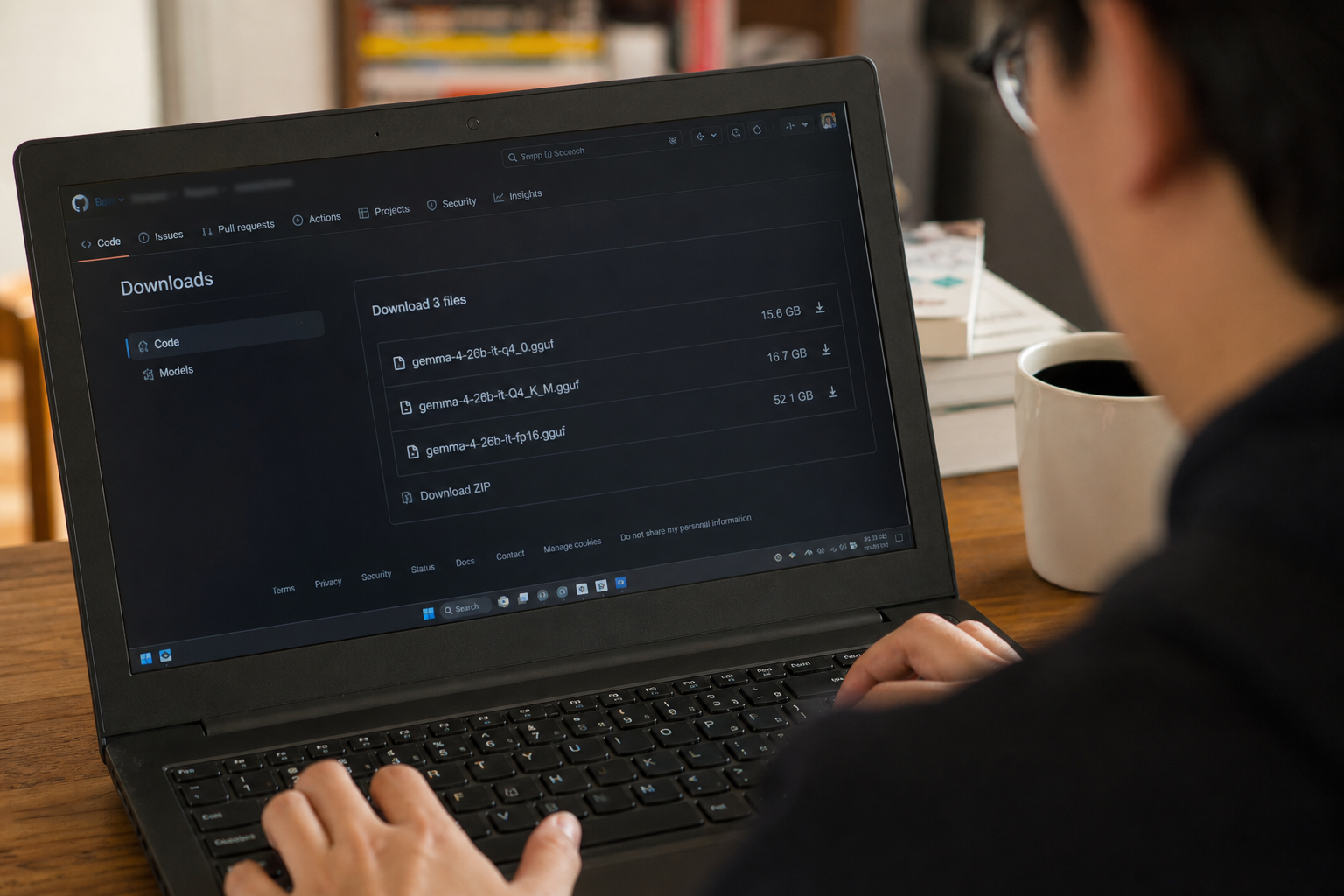
받아야 할 파일은 세 가지입니다. 메인 추론 모델, 투기적 디코딩용 드래프트 헤드, 그리고 이미지를 텍스트 토큰으로 변환해주는 멀티모달 프로젝터. 이 세 파일이 같은 폴더 안에 있어야 나중에 서버 실행 명령어가 한 줄로 끝납니다.
- 메인 모델:
gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf— Unsloth의 HuggingFace 저장소에 올라와 있고, 파일 크기는 약 16GB입니다. Q4는 4비트 양자화(원래 32비트 가중치를 4비트로 압축한 것), K_XL은 Unsloth가 적용한 정밀도 보정 방식을 의미합니다. 이 파일 하나만 받으면 Metal 가속 기준으로 약 58 tok/s가 나옵니다. - MTP 드래프트 헤드:
MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf— 같은 저장소 안의MTP/하위 폴더에 있습니다. 이 드래프트 헤드를 붙이면 생성 속도가 58에서 72 tok/s까지 올라갑니다. Q8_0이라 파일 자체는 크지 않아서 전체 모델 폴더가 약 17GB로 마무리됩니다. - 멀티모달 프로젝터:
mmproj-gemma-4-26B-A4B-it-bf16.gguf— 이미지 픽셀을 모델이 이해할 수 있는 토큰 벡터로 변환해주는 작은 변환기입니다. BF16 포맷이라 정밀도를 유지하면서도 메인 모델보다 훨씬 가볍습니다. 이 파일이 없으면 나중에 Pi 에이전트에 스크린샷을 붙여서 보내도 모델이 텍스트만 보게 됩니다.
세 파일을 내려받는 방법은 huggingface-cli를 쓰는 게 제일 편합니다. 저는 처음에 브라우저로 직접 받으려다 16GB짜리가 중간에 끊겨서 결국 CLI로 갔습니다. 아래처럼 --include 플래그로 파일 세 개를 한 번에 지정하면 됩니다.
huggingface-cli download unsloth/gemma-4-26B-A4B-it-GGUF \
--include "gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf" \
--include "MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf" \
--include "mmproj-gemma-4-26B-A4B-it-bf16.gguf" \
--local-dir models/unsloth-gemma-4-26B-A4B-it-GGUF
--local-dir로 저장 경로를 명시해두지 않으면 HuggingFace 캐시 디렉터리 안에 해시 폴더 구조로 쪼개져 들어가서 나중에 경로 찾기가 번거로워집니다. 처음부터 models/ 아래에 정리해두는 쪽이 실행 명령어를 짤 때 훨씬 수월합니다. 다운로드가 끝나면 폴더 안에 세 파일이 나란히 있는지 ls -lh models/unsloth-gemma-4-26B-A4B-it-GGUF/로 한 번 확인해보는 게 좋습니다. MTP 드래프트 헤드는 MTP/ 하위 폴더에 들어가 있으니 그것도 같이 확인합니다.
파일이 다 갖춰졌다면, 이제 이 세 파일을 어떻게 조합해서 실제로 58에서 72 tok/s를 끌어올리는지 — MTP 파라미터를 어떻게 튜닝하느냐가 관건입니다.
MTP(Multi-Token Prediction) 투기적 디코딩은 메인 모델이 토큰 하나를 생성할 때 드래프트 모델이 먼저 N개를 "예측"해 두고, 메인 모델이 그 예측을 한꺼번에 검증하는 방식입니다. 맞은 토큰은 그대로 쓰고, 틀린 토큰은 버리고 메인 모델이 다시 생성하는 식이라 — 정확도를 유지하면서 실질 처리 속도를 높일 수 있습니다.
드래프트 모델을 붙이는 명령어는 아래처럼 씁니다.
repos/llama.cpp/build/bin/llama-cli \
-m models/unsloth-gemma-4-26B-A4B-it-GGUF/gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf \
--model-draft models/unsloth-gemma-4-26B-A4B-it-GGUF/MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf \
--spec-type draft-mtp \
--spec-draft-n-max 3 \
-ngl 999 \
-fa on \
-c 4096 \
-n 128
여기서 핵심 파라미터는 --spec-draft-n-max입니다. 드래프트 모델이 한 번에 몇 개 토큰을 미리 예측할지를 결정하는 값인데, 이걸 얼마로 세팅하느냐가 실제 속도에 직결됩니다. Unsloth 가이드에서도 "2를 기본값으로 쓰되, 하드웨어마다 최적값이 다르니 1~6을 직접 스윕하라"고 권고하고 있습니다.
M1 Max 64GB 기준으로 1부터 6까지 직접 돌려본 결과는 이렇습니다.
--spec-draft-n-max | Generation tok/s |
|---|---|
| 1 | 68.4 |
| 2 | 72.0 |
| 3 | 72.2 |
| 4 | 70.7 |
| 5 | 63.7 |
| 6 | 61.2 |
3이 72.2 tok/s로 가장 빨랐고, 2도 72.0으로 사실상 차이가 없습니다. 4부터는 오히려 느려지고, 56은 드래프트 오버헤드가 검증 이득을 넘어서는 구간으로 보입니다. 드래프트 토큰이 많아질수록 검증 비용도 커지기 때문입니다. MTP 없이 메인 모델만 돌렸을 때 58.2 tok/s였던 것과 비교하면, 24% 속도 향상입니다. 프롬프트 처리 속도(295299 tok/s)는 드래프트 모델 유무와 관계없이 거의 그대로 유지됐습니다.
한 가지 덧붙이면, 저는 처음에 MLX가 애플 실리콘에 최적화된 프레임워크니까 당연히 더 빠를 거라고 생각했습니다. 그런데 직접 비교해보니 생각이 달라졌습니다. mlx-lm으로 Unsloth의 MLX 4-bit 모델을 돌렸을 때 45.8 tok/s, mlx-community 4-bit는 43.9 tok/s에 그쳤습니다. llama.cpp Metal 단독(58.2)보다도 느렸고, MTP 조합(72.2)과는 격차가 꽤 납니다. llama.cpp 쪽에 MTP 관련 최적화가 더 많이 쌓인 결과로 보입니다.
이 수치를 확인했다면, 이제 llama-cli 대신 llama-server로 OpenAI 호환 엔드포인트를 열어야 합니다. Pi 에이전트를 비롯한 외부 툴이 API로 붙으려면 서버 모드가 필요하고, 거기에 멀티모달 프로젝터 파일까지 함께 로드해야 이미지 입력이 가능해집니다. 그런데 서버를 터미널에 띄워두면 세션을 닫는 순간 프로세스가 같이 죽는 문제가 생깁니다. 그래서 tmux 래퍼 스크립트가 필요합니다.

tmux는 터미널 멀티플렉서입니다. 쉽게 말하면, 터미널 창을 닫아도 그 안에서 돌아가던 프로세스가 살아 있게 해주는 도구입니다. brew install tmux 한 줄로 설치되고, 이미 체크리스트에서 설치했다면 바로 쓸 수 있습니다.
직접 해봤더니 매번 긴 llama-server 명령어를 터미널에 치는 게 꽤 번거로웠습니다. 그래서 래퍼 스크립트를 하나 만들어두면 이후에는 파일 하나만 실행하면 됩니다.
- 스크립트 작성 — 프로젝트 루트에 start_server.sh라는 이름으로 아래 내용을 작성합니다.
#!/bin/bash
SESSION="llama-server"
tmux new-session -d -s "$SESSION" \
repos/llama.cpp/build/bin/llama-server \
-m models/unsloth-gemma-4-26B-A4B-it-GGUF/gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf \
--model-draft models/unsloth-gemma-4-26B-A4B-it-GGUF/MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf \
--spec-type draft-mtp \
--spec-draft-n-max 3 \
--mmproj models/unsloth-gemma-4-26B-A4B-it-GGUF/mmproj-gemma-4-26B-A4B-it-BF16.gguf \
-ngl 999 \
-fa on \
-c 8192 \
--host 0.0.0.0 \
--port 8080
echo "서버가 tmux 세션 '$SESSION'에서 시작됐습니다."
echo "접속 확인: curl http://localhost:8080/v1/models"
echo "세션 확인: tmux attach -t $SESSION"
- 실행 권한 부여 및 서버 시작 — 파일을 저장한 뒤 실행 권한을 주고 스크립트를 실행합니다.
tmux new-session -d플래그의-d가 핵심인데, detached 모드로 세션을 만들어서 터미널을 닫아도 서버가 계속 돌아갑니다.
chmod +x start_server.sh
./start_server.sh
-c 8192는 앞 섹션에서 쓴 4096 대신 컨텍스트를 두 배로 늘린 값입니다. 코딩 에이전트는 도구 호출을 여러 번 반복하면서 컨텍스트가 금방 차기 때문에, 메모리 여유가 있다면 8192 이상으로 설정해두는 편이 실제 작업 중에 훨씬 덜 끊깁니다. (M1 Max 64GB 기준으로는 16384까지 올려도 안정적으로 동작하는 걸 확인했습니다.)
- 엔드포인트 확인 — 서버가 뜨는 데 모델 파일 로드 시간까지 포함해서 약 20~30초 걸립니다. 그 이후에 아래 curl 명령어로 엔드포인트를 찔러봅니다.
curl http://localhost:8080/v1/models
응답으로 {"object":"list","data":[{"id":"gemma-4-26B-A4B-it-UD-Q4_K_XL",...}]} 형태의 JSON이 오면 서버가 정상적으로 올라온 겁니다. 아무 응답이 없거나 Connection refused가 뜨면 tmux attach -t llama-server로 세션에 들어가 오류 로그를 직접 확인해보면 됩니다. 로그에서 llm_load_tensors: offloaded 999/999 layers to GPU라는 줄이 보이면 Metal 가속이 제대로 걸린 상태입니다.
서버가 떠 있는 걸 확인했다면, 이제 Pi 에이전트를 이 엔드포인트에 연결하고 멀티모달 프로젝터까지 활용하는 설정으로 넘어갈 차례입니다.
Pi 에이전트를 로컬 서버에 연결하는 건 생각보다 간단합니다. 핵심은 Pi가 사용하는 models.json 파일에 로컬 프로바이더 항목을 하나 추가하는 것입니다.
- models.json 편집 — Pi의 설정 파일은 보통
~/.pi/models.json경로에 있습니다. 파일을 열면 OpenAI나 Anthropic 같은 기존 프로바이더 항목들이 배열 형태로 나열돼 있는데, 거기에 아래처럼 로컬 엔드포인트를 가리키는 항목을 추가하면 됩니다.
{
"id": "local-gemma4",
"provider": "openai",
"baseURL": "http://127.0.0.1:8080/v1",
"apiKey": "none",
"model": "gemma-4-26B-A4B-it-UD-Q4_K_XL"
}
apiKey를 "none"으로 넣는 이유는 로컬 llama.cpp 서버가 인증 없이 동작하기 때문입니다. provider는 "openai"로 지정하면 Pi가 OpenAI 호환 API 형식으로 요청을 보냅니다. 저는 처음에 baseURL 끝에 슬래시를 붙였다가 404가 떠서 한참 헤맸는데, http://127.0.0.1:8080/v1처럼 슬래시 없이 끝내는 게 맞습니다.
-
멀티모달 입력 활성화 — 이미지(멀티모달) 기능을 쓰려면 한 가지를 더 추가해야 합니다. 같은 항목 안에
"input": ["text", "image"]를 넣어줘야 Pi가 이 모델에 스크린샷을 붙여서 보낼 수 있다는 걸 인식합니다. 이 줄이 없으면 Pi는 해당 모델을 텍스트 전용으로 취급하고 이미지 첨부 옵션 자체를 UI에서 숨겨버립니다. 멀티모달 프로젝터 파일(BF16)을 Step 2에서 이미 받아뒀기 때문에,llama.cpp서버 실행 시--mmproj플래그로 해당 파일 경로를 지정했다면 이쪽 준비는 끝난 상태입니다. Pi 설정에서input배열만 맞춰주면 두 쪽이 연결됩니다. -
연결 확인 — 설정 파일을 저장했으면 터미널에서
pi --list-models를 실행해서local-gemma4항목이 목록에 뜨는지 확인합니다. 여기서 보이지 않는다면 JSON 문법 오류(쉼표 빠짐, 괄호 불일치)를 먼저 의심해보면 좋습니다.jq . ~/.pi/models.json을 한 번 돌려보면 파싱 오류 위치를 바로 잡아줍니다.
모델이 목록에 올라왔다면 실제로 스크린샷을 붙여서 써볼 차례입니다. Pi에서 local-gemma4를 선택한 뒤 프롬프트 입력창에 이미지를 드래그하거나 클립보드에서 붙여넣기하면 됩니다. 저는 브라우저에서 UI 버그가 생긴 화면을 캡처해서 "이 레이아웃이 왜 깨지는지 CSS를 찾아서 고쳐줘"라고 던졌는데, 에이전트가 스크린샷을 읽고 관련 파일을 직접 열어 수정하는 걸 보고 꽤 놀랐습니다 (인터넷 없이, 내 맥 위에서 다 돌아가는 상태로요). 응답 속도는 Step 3에서 맞춰둔 72 tok/s 그대로 유지됩니다. 에이전트가 tool call을 여러 번 반복하는 작업일수록 이 속도 차이가 체감됩니다.
이 정도 설정이 완성되면 인터넷이 끊겨도, API 비용이 신경 쓰여도, 코드에 민감한 정보가 섞여 있어도 망설임 없이 에이전트를 돌릴 수 있습니다. 다만 실제로 쓰다 보면 빌드 실패, MTP 마크업 깨짐 같은 예상치 못한 지점에서 막히는 경우가 생깁니다.
저도 처음 빌드할 때 아무 오류 없이 넘어가진 않았습니다. 막히는 지점이 생각보다 정해져 있어서, 미리 알아두면 시간을 상당히 아낄 수 있습니다.
첫 번째는 Metal 빌드 실패입니다. cmake 단계에서 GGML_METAL=ON 플래그를 넣었는데도 빌드가 죽는 경우, 대부분 Xcode Command Line Tools 버전이 낮아서 생깁니다. xcode-select --version으로 확인했을 때 2400번대 미만이면 sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer로 풀 Xcode를 바라보게 바꿔주면 해결됩니다. Homebrew로 깔린 llvm이 시스템 clang과 충돌하는 경우도 있는데, 이때는 PATH에서 /opt/homebrew/opt/llvm/bin을 제거하고 다시 cmake를 돌려보면 됩니다.
두 번째는 모델 weight key 불일치 오류입니다. llama.cpp 서버를 띄울 때 llama_model_load: error loading model 뒤에 key not found 메시지가 붙어 나오면, 다운받은 GGUF 파일과 llama.cpp 빌드 시점이 맞지 않는 겁니다. Gemma 4 아키텍처는 비교적 최근에 llama.cpp에 들어왔기 때문에, 오래된 커밋으로 빌드한 바이너리에서는 인식을 못 합니다. git pull 후 build 디렉터리를 지우고 처음부터 다시 빌드하는 것이 가장 확실합니다. 저는 이걸 모르고 모델 파일을 다시 받는 데 30분을 썼습니다 (파일 문제가 아니라 바이너리 문제였는데).
세 번째는 MTP가 stop 토큰을 놓치는 현상입니다. 이게 조금 독특한 문제인데, --spec-type draft-mtp를 켰을 때 응답 끝에 <end_of_turn> 토큰이 잘려나가거나, 마크다운 코드블록 닫는 ```이 빠진 채로 출력이 끊기는 경우가 보고되고 있습니다. Pi 에이전트처럼 응답 파싱이 엄격한 클라이언트에서는 tool call 결과가 망가지는 원인이 됩니다. Unsloth 가이드에서는 --spec-draft-n-max 값을 낮추면 완화된다고 언급하는데, 실제로 4 이상에서 이 현상이 더 자주 발생합니다. M1 Max 기준으로 3이 속도와 안정성 모두 괜찮았던 이유가 여기에도 있습니다. 현재로서는 값을 2~3으로 유지하면서 지켜보는 것이 현실적입니다.
네 번째는 64GB 미만 맥에서 생각보다 느린 속도입니다. 소스에서 테스트한 환경이 M1 Max 64GB 통합 메모리인데, 메인 모델(Q4_K_XL, ~16GB)에 Q8 MTP 드래프트 헤드까지 올리면 실제 메모리 사용량이 17GB를 넘습니다. 32GB 맥에서는 OS와 다른 프로세스가 차지하는 메모리까지 합산되면 모델 레이어 일부가 GPU 대신 CPU로 내려가는 경우가 생깁니다. -ngl 999는 모든 레이어를 GPU에 올리라는 플래그인데, 메모리가 부족하면 llama.cpp가 조용히 일부 레이어를 CPU로 떨구면서 속도가 뚝 떨어집니다. 이때는 -ngl 값을 낮춰서 명시적으로 레이어를 나누거나, 컨텍스트 크기(-c)를 4096보다 줄여서 KV 캐시 점유를 낮추는 방법을 써볼 수 있습니다. 36GB나 48GB 모델을 쓰고 싶다면 그냥 더 작은 양자화 포맷(Q3_K_M 계열)으로 내려가는 게 체감상 낫습니다.
💡 핵심:
key not found오류와 stop 토큰 누락은 모두 모델 파일이 아니라 바이너리·파라미터 문제입니다. 파일을 다시 받기 전에git pull후 재빌드,--spec-draft-n-max값 조정을 먼저 시도하세요.
네 가지 함정을 모두 피해 서버가 안정적으로 돌아가고 Pi까지 붙었다면, 이 셋업을 기반으로 모델만 교체해서 다른 용도로 확장하는 것도 자연스럽게 이어집니다.
여기까지 왔으면 한 번 직접 재보는 게 좋습니다. 느낌으로 "빠른 것 같은데"로 끝내면 나중에 모델 바꿀 때 비교 기준이 없어집니다.
측정 방법은 간단합니다. Step 3에서 썼던 벤치마크 프롬프트를 그대로 씁니다.
Write a compact Python function that parses a unified diff and returns the changed file paths. Then explain two edge cases.
llama-cli에 -n 128을 달아 128토큰을 생성하고, 출력 끝에 찍히는 eval time 줄을 보면 됩니다. 저도 처음엔 그냥 대화해보고 "뭔가 빠르네"로 넘어갔는데, 막상 숫자를 재보니 MTP를 켜기 전후 차이가 눈에 확 들어왔습니다. M1 Max 64GB 기준으로 58.2 tok/s → 72.2 tok/s, 약 24% 향상이 숫자로 찍히는 순간이 꽤 묘하게 기분 좋습니다.
숫자가 나왔으면 이제 다음 선택지를 볼 여유가 생깁니다. 요즘 커뮤니티에서 자주 언급되는 게 Qwen3 30B-A3B입니다. (Qwen3.6이라 불리기도 하는 MoE 계열 모델입니다 — MoE는 전체 파라미터 중 일부만 활성화해서 추론하는 구조라, 파라미터 수 대비 메모리 효율이 좋습니다.) 같은 M1 Max 환경에서 Q4 양자화 기준 약 55 tok/s 전후로 보고되고 있습니다. Gemma 4보다 느리지만, 코드 추론 벤치마크에서는 경쟁력 있고 멀티모달 프로젝터 없이 구성이 단순해진다는 장점이 있습니다. 지금 Pi에 연결해둔 구조 그대로 models.json의 모델 경로만 바꾸면 바로 시험해볼 수 있어서 진입 비용이 낮습니다.
스택 자체를 바꾸고 싶다면 LM Studio나 Ollama도 선택지입니다. 두 쪽 다 GUI 또는 ollama run 한 줄로 서버가 올라가고 OpenAI 호환 엔드포인트를 같은 포트로 내줍니다. Pi 설정에서 base_url만 그대로 두면 이쪽으로도 붙습니다. 다만 llama.cpp를 직접 빌드한 이번 방식과 비교하면 MTP 드래프트 헤드 같은 세부 플래그를 건드릴 여지가 줄어듭니다. 속도보다 편의성이 우선이라면 Ollama, 수치를 직접 튜닝하고 싶다면 지금 구조를 그대로 유지하는 편이 낫습니다.
저는 지금도 이 셋업을 그냥 쓰고 있습니다. 인터넷이 끊겨도, API 요금이 신경 쓰여도, 코드베이스를 외부로 보내기 찝찝해도 — 터미널 열고 ./start_server.sh 치면 됩니다.
Q. MacBook 16GB 모델로도 이 셋업을 돌릴 수 있나요?
A. 권장하지 않습니다. 메인 모델 파일만 16GB를 넘기 때문에 macOS와 에이전트 프로세스까지 합치면 페이지 아웃이 발생해 속도가 크게 떨어집니다. 최소 32GB 통합 메모리를 갖춘 Apple Silicon Mac이 필요합니다.
Q. MLX가 Apple Silicon 전용인데 왜 llama.cpp보다 느린가요?
A. 이 케이스에서는 같은 4-bit 모델 기준으로 mlx-lm이 43~45 tok/s인 반면 llama.cpp + Metal은 58 tok/s, MTP까지 더하면 72 tok/s가 나왔습니다. '플랫폼 최적화 = 무조건 빠름'이라는 전제가 항상 맞지는 않으며, 직접 수치를 재보는 것이 중요합니다.
Q. Pi 대신 다른 에이전트 도구를 써도 이 서버에 붙일 수 있나요?
A. 네, llama.cpp 서버가 OpenAI 호환 API를 내주기 때문에 base_url과 포트만 맞추면 대부분의 도구가 그대로 붙습니다. LM Studio나 Ollama로 서버를 교체하는 것도 Pi 설정의 base_url만 바꾸면 됩니다.