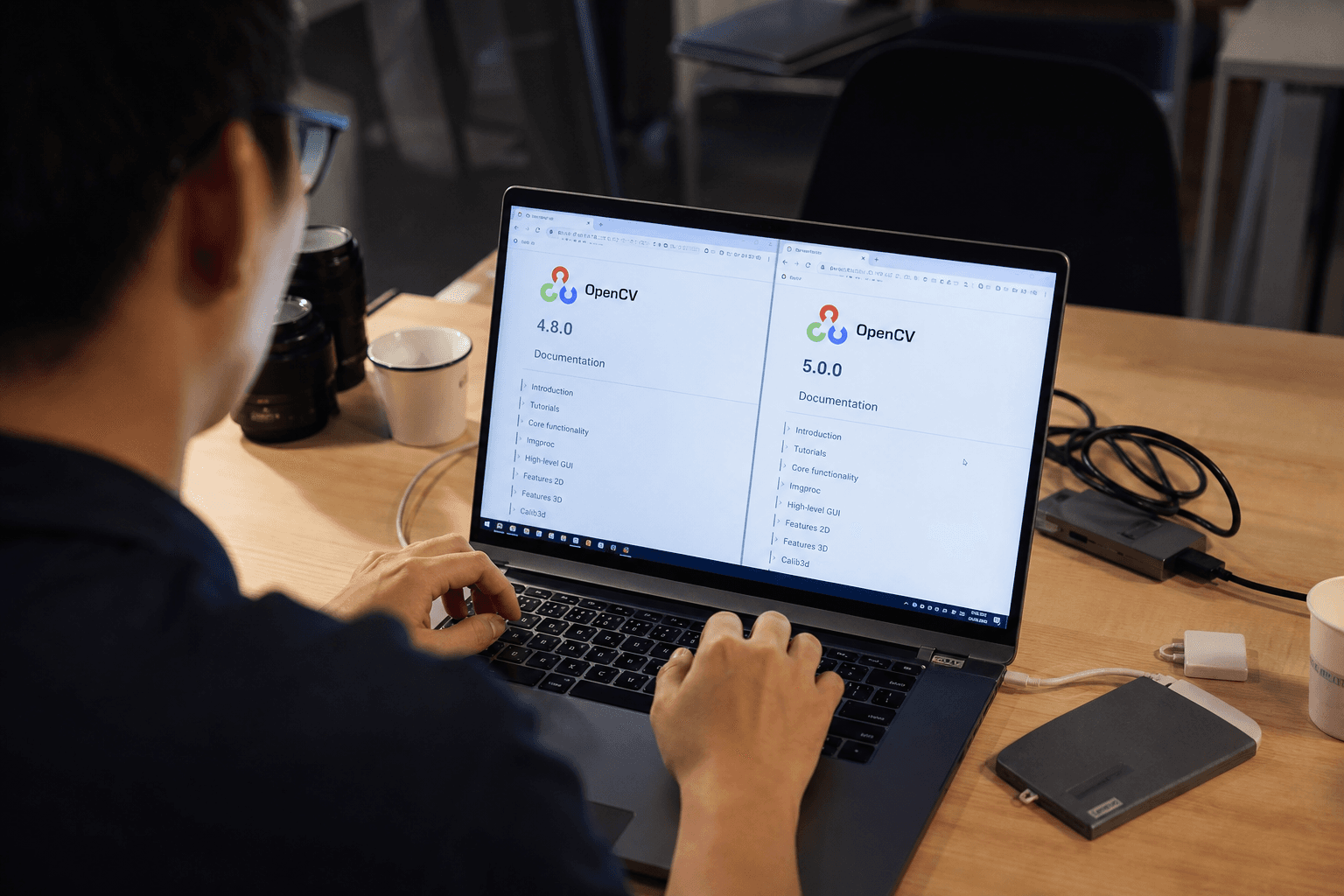
OpenCV를 써본 사람이라면 공감할 겁니다. cv2.dnn.readNetFromONNX()를 호출하고, 조용히 손가락을 교차하는 그 순간. 모델이 로드될 수도 있고, "unsupported operator" 에러가 반길 수도 있는 그 룰렛. OpenCV 5는 그 불확실성을 정면으로 겨냥한 릴리스입니다.
2026년 6월 4일, OpenCV 팀이 OpenCV 5를 공개했습니다. GitHub 스타 86,000개, 하루 설치 100만 건 이상의 라이브러리가 내놓은 첫 번째 메이저 버전 업그레이드입니다. 핵심은 크게 세 가지입니다.
- DNN 엔진을 밑바닥부터 다시 썼고
- ONNX 연산자 지원율을 22%에서 80%까지 끌어올렸으며
- LLM·VLM을 OpenCV 안에서 직접 실행할 수 있는 기반을 넣었습니다
거기에 하드웨어 가속 경로 통합, Python 연동 개선, 3D 비전 툴링 확장까지 따라왔습니다. OpenCV 팀 스스로 "OpenCV 역사에서 가장 중요한 릴리스 중 하나"라고 표현했는데, 변경 목록을 보면 과장이 아닙니다.
왜 지금이냐는 질문에 대한 답은 지난 몇 년간 컴퓨터 비전이 어떻게 바뀌었는지를 보면 나옵니다. OpenCV 4가 나왔을 때와 비교해서, 지금 프로덕션 환경은 전혀 다른 모습입니다. 같은 코드가 노트북, 서버, ARM 칩, Snapdragon 플랫폼, 엣지 디바이스에서 모두 효율적으로 돌아야 합니다. 트랜스포머 기반 모델이 표준이 됐고, 개발자들은 Python 퍼스트 워크플로를 당연하게 여깁니다. OpenCV 4의 DNN 모듈은 그 변화 속도를 따라가기 어려웠습니다. 새 엔진, 새 API 설계, LLM 지원은 그 간극을 메우기 위한 선택입니다. 각각이 실제로 어떻게 작동하는지는 ONNX 지원율 수치부터 풀어보면 윤곽이 잡힙니다.

ONNX 지원율이 22%에서 80%로 뛰었다는 숫자, 처음 봤을 때 저도 잘못 읽었나 싶었습니다. 22%면 사실상 "운이 좋으면 된다" 수준이니까요.
이 숫자를 만든 핵심은 엔진 자체를 다시 짰다는 데 있습니다. OpenCV 4의 DNN 모듈은 레이어(layer) 단위 실행 방식이었습니다. 모델을 불러오면 레이어를 하나씩 순서대로 처리하는 구조인데, 문제는 현대 모델이 그런 단순 직렬 흐름으로 설계되지 않는다는 점입니다. 트랜스포머에는 조건 분기(If)와 반복(Loop)이 들어가고, 입력 크기가 추론 시점에 정해지는 동적 shape(dynamic shape)도 당연하게 쓰입니다. 레이어 단위 엔진은 이 구조를 만나면 모르는 연산자라고 에러를 뱉거나, 아예 모델 로드 자체를 거부했습니다.
OpenCV 5는 이걸 그래프 기반 실행 엔진(graph-based execution engine)으로 교체했습니다. 모델 전체를 계산 그래프로 파싱한 뒤, 노드 간 데이터 흐름과 의존 관계를 분석해서 실행 순서를 결정합니다. 쉽게 말하면, 악보를 한 음씩 읽던 방식에서 전체 악보를 먼저 보고 연주 계획을 짜는 방식으로 바뀐 겁니다. 덕분에 If·Loop 같은 제어 흐름 서브그래프가 그래프 노드로 자연스럽게 편입되고, 동적 shape도 런타임에 shape 추론을 돌려 처리할 수 있게 됐습니다.
"The new engine is built around a graph-based execution model. It parses the full ONNX graph, resolves dynamic shapes at runtime, and handles control flow subgraphs including If and Loop nodes." — OpenCV 5 Deep Dive
하나 더 체감되는 변화가 Attention 퓨전(Attention fusion)입니다. 트랜스포머의 Self-Attention 블록은 ONNX로 익스포트하면 MatMul, Transpose, Softmax 등 수십 개 연산자로 쪼개집니다. 기존 엔진은 이걸 그대로 하나씩 실행했는데, 새 엔진은 그래프 분석 단계에서 이 패턴을 인식해 단일 Attention 퓨전 커널 하나로 합칩니다. 연산 횟수가 줄고 메모리 이동도 줄어드니 속도가 올라갑니다. 수십 개 연산이 하나로 묶이는 이 과정을 operator fusion이라고 하는데, 그래프 전체를 미리 보는 엔진이 아니면 구조적으로 불가능한 최적화입니다.
지원 연산자 수 자체도 늘었습니다. ONNX opset 기준으로 이전 버전이 커버하지 못했던 연산자 다수가 새 엔진에 포함됐고, 그 결과가 80%라는 수치로 나타납니다. 80%가 100%가 아닌 이유는 일부 실험적 opset이나 커스텀 연산자가 아직 미지원 상태이기 때문이지만, 실무에서 주로 쓰이는 YOLO, 트랜스포머 기반 탐지 모델, Vision Transformer 계열이 별도 변환 없이 로드된다는 건 체감 차이가 큽니다. 이전엔 모델을 cv2.dnn.readNetFromONNX에 넣기 전에 opset 버전을 낮추거나 연산자를 수동으로 우회하는 작업이 필요했는데, 그 단계가 상당 부분 사라집니다.

새 DNN 엔진이 그래프를 더 넓게 읽을 수 있게 됐다고 해서, 기존 코드를 전부 고쳐야 한다면 아무도 업그레이드하지 않을 겁니다. OpenCV 5가 그 부분을 꽤 영리하게 처리했습니다.
핵심은 세 개의 백엔드를 단일 API로 감싸는 구조입니다.
| 엔진 | 설명 |
|---|---|
ENGINE_CLASSIC | OpenCV 4까지 쓰던 기존 레거시 엔진 |
ENGINE_NEW | 이번에 새로 설계된 그래프 기반 엔진 |
ENGINE_ORT | Microsoft의 ONNX Runtime을 직접 백엔드로 사용하는 옵션 |
세 가지 모두 cv2.dnn.readNetFromONNX로 모델을 불러오고, net.forward()로 추론을 실행하는 인터페이스는 동일합니다. 엔진을 바꾸는 건 net.setEngineType(cv2.dnn.ENGINE_NEW) 한 줄입니다. 코드 구조를 건드릴 필요가 없습니다.
그중에서 기본값인 ENGINE_AUTO가 실질적으로 가장 눈에 띄는 부분입니다. ENGINE_AUTO는 모델을 로드할 때 ONNX 그래프를 먼저 분석해서, 새 엔진이 해당 그래프의 연산자를 전부 처리할 수 있으면 ENGINE_NEW로 실행하고, 지원하지 않는 연산자가 포함돼 있으면 ENGINE_CLASSIC으로 자동 폴백합니다. 사용자가 직접 호환성을 확인하거나 엔진을 수동으로 지정할 필요 없이, 런타임이 그래프를 보고 스스로 결정하는 방식입니다. OpenCV 공식 블로그 설명에 따르면, 이 자동 선택 로직 덕분에 OpenCV 4 기반 파이프라인을 그대로 OpenCV 5로 올려도 동작이 깨지지 않는 것이 설계 목표였습니다. 일종의 안전망입니다 — 새 엔진이 받아줄 수 있으면 조용히 업그레이드되고, 그렇지 않으면 예전 방식으로 처리됩니다.
⚠️ 주의: OpenCV 5.0 출시 시점 기준으로 새 DNN 엔진은 CPU 전용입니다. GPU 추론 파이프라인에서 새 엔진의 속도 개선을 기대하고 업그레이드하면 기대치가 어긋날 수 있습니다. GPU 지원은 다음 릴리스 로드맵에 명시되어 있습니다.
한 가지 현실적인 제약은 짚고 넘어가야 합니다. OpenCV 5.0 출시 시점 기준으로 새 DNN 엔진은 CPU 전용입니다. GPU 가속은 아직 지원되지 않습니다. GPU 실행이 필요한 경우라면 ENGINE_ORT 백엔드를 통해 ONNX Runtime의 CUDA execution provider를 연결하는 경로를 쓰거나, 기존처럼 CUDA 백엔드를 별도로 지정해야 합니다. OpenCV 팀은 새 엔진의 네이티브 GPU 지원을 다음 릴리스 목표로 명시해뒀습니다. 이 제약이 얼마나 큰 문제냐는 워크로드에 따라 다릅니다. 엣지 디바이스나 ARM 기반 보드처럼 CPU 추론이 주인 환경에서는 지금 당장 새 엔진의 혜택을 온전히 누릴 수 있고, GPU 서버에서 대용량 배치 추론을 돌리는 쪽은 ENGINE_ORT를 쓰거나 GPU 지원이 들어올 다음 버전을 기다리는 게 현실적입니다.

공개된 수치만 놓고 보면 꽤 자신감 있는 주장입니다. OpenCV 팀이 직접 공개한 벤치마크에 따르면, 새 DNN 엔진은 ONNX Runtime 대비 OWLv2에서 36%, BiRefNet에서 32% 빠른 추론 속도를 기록했습니다. 처음 숫자만 봤을 때 저도 "설마?" 싶었는데, 측정 조건을 뜯어보면 어느 정도 납득이 됩니다.
핵심은 Attention Fusion과 그래프 최적화 패스 덕분입니다. 새 엔진은 모델을 불러올 때 ONNX 그래프 전체를 한 번에 분석해서, 여러 개의 작은 연산 노드(예: MatMul + Add + Softmax)를 하나의 커널로 합쳐버립니다 (출처: OpenCV 5 Deep Dive, opencv.org). 이 합치는 작업을 "퓨전"이라고 부르는데, 쉽게 말하면 중간 결과를 메모리에 썼다 읽는 왕복 횟수를 줄이는 것입니다. OWLv2나 BiRefNet처럼 Transformer 기반 아키텍처에서 이 효과가 두드러지는 이유는, Attention 레이어 자체가 이런 작은 연산의 연속으로 구성되어 있기 때문입니다. ONNX Runtime도 동일한 방향으로 최적화를 해왔지만, OpenCV 새 엔진은 자체 그래프 패스를 OpenCV의 CPU 백엔드와 더 밀착해서 짰다는 게 팀의 설명입니다.
커뮤니티 실측 데이터도 비슷한 방향을 가리킵니다. 여러 사용자가 YOLOv8m 기준으로 OpenCV 4 DNN 대비 추론 시간이 255ms에서 185ms로 줄었다고 보고했습니다. 약 27% 개선인데, 공식 수치(32~36%)보다는 조금 낮습니다. 차이가 나는 건 당연합니다. 공식 벤치마크는 모델·배치 크기·CPU 세대까지 통제한 조건이고, 커뮤니티 측정은 각자의 장비에서 돌린 결과니까요. 그래도 방향성은 일치합니다. 새 엔진이 체감상 느려지는 경우는 지금까지 보고된 게 없고, 적어도 동등하거나 빠르다는 게 현재까지의 공통된 결론입니다.
다만 한 가지 조건을 짚어두는 게 좋습니다. 이 수치는 모두 CPU 추론 기준입니다. 앞서 언급했듯 새 엔진의 GPU 지원은 아직 로드맵 단계라, GPU를 쓰는 파이프라인에서는 ENGINE_ORT 경로가 현실적인 선택입니다. 즉 "ONNX Runtime보다 빠르다"는 주장은 CPU-only 시나리오에서 유효한 이야기이고, GPU 환경에서는 아직 직접 비교 자체가 성립하지 않습니다. 벤치마크를 볼 때 이 전제를 빼놓으면 기대치가 어긋날 수 있습니다.

OpenCV가 LLM을 돌린다는 말을 처음 들었을 때, 저도 잠깐 멈칫했습니다. "그건 Hugging Face나 llama.cpp 쪽 얘기 아닌가?" 싶었거든요. 그런데 공식 릴리즈 문서를 읽어보니 단순히 모델 파일을 불러오는 수준이 아니었습니다.
OpenCV 5의 새 DNN 엔진은 텍스트 생성에 필요한 인프라 전체를 라이브러리 안으로 끌어들였습니다. 구체적으로는 토크나이저(tokenizer), KV 캐시(key-value cache), 그리고 오토리그레시브 디코딩(autoregressive decoding) 루프까지 포함됩니다. KV 캐시는 트랜스포머가 이전 토큰의 연산 결과를 재사용하는 구조인데, 이게 없으면 긴 문장을 생성할 때마다 처음부터 다시 계산해야 해서 속도가 급격히 떨어집니다. 이 부분을 OpenCV 쪽에서 직접 관리한다는 게 핵심입니다. 공식 문서에 따르면 현재 공식 지원 모델은 Qwen 2.5, Gemma 3, PaliGemma이며, 이들 모델을 ONNX로 내보낸 뒤 cv2.dnn.TextGenerationModel API로 로드해서 사용하는 방식입니다. (출처: OpenCV 5 공식 릴리즈 포스트) PaliGemma는 구글이 내놓은 비전-언어 모델(VLM)로, 이미지를 입력받아 텍스트로 설명하거나 질문에 답하는 구조입니다. 즉 cv2.imread로 불러온 이미지를 그대로 VLM 추론에 넘길 수 있다는 뜻이고, 이미지 전처리부터 언어 생성까지 파이프라인 전체가 OpenCV 단일 프로세스 안에서 닫히게 됩니다.
이 구조가 실질적으로 의미 있는 이유는 의존성 체인이 짧아지기 때문입니다. 기존에 VLM 추론 파이프라인을 짜려면 Transformers 라이브러리, 토크나이저 패키지, 별도 런타임, 그리고 이미지 전처리 코드를 각각 연결해야 했습니다. 엣지 디바이스나 산업용 장비처럼 패키지 설치가 제한된 환경에서는 이 의존성 하나하나가 배포 장벽이 됩니다. OpenCV 5는 그 장벽을 상당 부분 걷어냅니다. 물론 현재 엔진이 CPU 전용이라는 제약은 앞 섹션에서 이미 짚었고, 이 점은 LLM 쪽에도 그대로 적용됩니다. 파라미터가 수십억 개인 모델을 CPU로 돌리면 속도가 기대에 미치지 못할 수 있어서, 지금 시점에서는 경량 VLM 또는 양자화된 소형 모델에서 가장 현실적인 결과가 나옵니다.
LLM·VLM 외에도 이번 릴리즈에서 체감이 큰 추가 기능이 둘 있습니다.
- LaMa(Large Mask inpainting) 기반 인페인팅: LaMa는 퓨리에 합성곱(Fourier convolution)을 활용해서 큰 마스크 영역을 자연스럽게 채우는 딥러닝 모델인데, 이전에는 별도 환경에서 모델을 구동해야 했습니다. OpenCV 5에서는
cv2.xphoto.LaMaInpainter로 바로 호출할 수 있습니다. - ALIKED + LightGlue 조합의 딥러닝 피처 매칭: ALIKED는 학습 기반 키포인트 검출기, LightGlue는 그 키포인트들 사이의 대응점을 찾는 경량 매처입니다. SIFT나 ORB 같은 고전적인 방법에 비해 조명 변화나 시점 변화에 훨씬 강한 매칭 결과를 보여주는데, 이 쌍을 OpenCV 안에서 바로 쓸 수 있게 됐습니다. 드론 측위, 3D 재구성, AR 트래킹처럼 강건한 피처 매칭이 필수인 파이프라인에서 외부 의존성을 줄이면서 성능도 올릴 수 있는 경우입니다.
이렇게 놓고 보면 OpenCV 5가 노리는 방향이 보입니다. 단순히 기존 기능을 빠르게 만드는 게 아니라, 이미지·비디오 처리부터 언어 이해까지 한 라이브러리 안에서 끝낼 수 있는 범위를 넓히는 것입니다.

결론부터 말하면, 지금 당장 올려도 되는 경우와 조금 기다리는 게 나은 경우는 생각보다 명확하게 갈립니다.
YOLO 계열 모델을 프로덕션 서버에서 돌리고 있다면, 업그레이드 효과가 가장 빠르게 체감되는 케이스입니다. 앞 섹션에서 확인한 YOLOv8m 기준 255ms → 185ms 수치는 단순 데모가 아니라 배치 없이 단일 이미지 추론 기준입니다. 초당 처리량이 중요한 API 서버라면 같은 하드웨어에서 처리 여유가 생기고, 그 여유를 더 많은 동시 요청을 받는 데 쓸 수 있습니다. 이 경우 적용 순서는 단순합니다. 모델을 ONNX로 익스포트하고 (torch.onnx.export 혹은 ultralytics export format=onnx), cv2.dnn.readNetFromONNX에 넣은 뒤 엔진 플래그를 ENGINE_AUTO로 두면 됩니다. 기존 코드 수정은 거의 없습니다. 단, GPU 가속은 아직 DNN 엔진에 완전히 올라오지 않았으니 (로드맵 상 다음 단계), 현재 CUDA 백엔드를 쓰는 파이프라인이라면 속도 기대치를 CPU 기준으로 잡아야 합니다.
엣지나 임베디드 환경 — Raspberry Pi, Jetson Nano, Snapdragon 기반 보드 등 CPU 전용 파이프라인이라면 사실상 업그레이드 이유가 가장 충분한 환경입니다. 새 DNN 엔진에 들어간 Attention 퓨전과 연산자 최적화는 GPU가 없는 환경에서 체감 폭이 더 큽니다. GPU가 있으면 어차피 하드웨어가 병목을 어느 정도 커버해주지만, CPU만으로 추론을 돌릴 때는 소프트웨어 레벨 최적화가 그대로 레이턴시에 반영됩니다. 추가로 ONNX 지원율이 22%에서 80%대로 올라간 덕분에, 예전에 "이 연산자는 지원 안 됨" 오류로 포기했던 최신 경량 모델(MobileNetV4, EfficientViT 계열 등)을 다시 시도해볼 수 있습니다. 동적 shape를 요구하는 모델도 이제 에러 없이 로딩되는 경우가 많아졌습니다. 임베디드 프로젝트에서 ONNX 익스포트 후 테스트만 해봐도 통과 여부가 달라진 걸 금방 확인할 수 있습니다.
파노라마 스티칭, SfM(Structure from Motion), NeRF 전처리처럼 피처 매칭이 파이프라인 병목인 프로젝트라면 이번 릴리스가 꽤 다른 의미입니다. 기존에는 SIFT·ORB 같은 고전 알고리즘을 쓰거나, ALIKED·LightGlue를 쓰고 싶으면 별도 레포를 클론해서 PyTorch 환경을 따로 구성해야 했습니다. OpenCV 5에서는 이 두 모델이 cv2.xfeatures2d 안에 직접 들어왔습니다 (소스: OpenCV 5 공식 릴리스 노트). 파이프라인을 PyTorch 의존성 없이 OpenCV 하나로 유지할 수 있게 됩니다. 배포 환경이 단순해지는 건 생각보다 실용적인 이점입니다. 도커 이미지 크기, 의존성 충돌, 버전 고정 문제가 한꺼번에 줄어듭니다.
반면 지금 당장 올리지 않는 게 나은 경우도 있습니다.
- CUDA 백엔드를 적극적으로 활용 중인 GPU 추론 파이프라인이라면, 새 DNN 엔진의 GPU 지원이 완성될 때까지 기다리는 편이 낫습니다.
- 레거시 Caffe 모델이나 TensorFlow
.pb파일을 직접 로딩하는 파이프라인은ENGINE_CLASSIC으로 폴백되기는 하지만, 장기적으로는 ONNX로 재익스포트하는 방향을 잡아두는 게 좋습니다. - OpenCV 4에서 5로 올릴 때 API 브레이킹 체인지는 크지 않지만, 일부 deprecated 함수가 정리됐으니 CI에서 경고 로그는 한 번 확인해볼 필요가 있습니다.
pip 설치 기준으로는 pip install opencv-python==5.0.*으로 바로 시도해볼 수 있고 (6월 8일 이후 배포 예정), 프로덕션 반영 전에 기존 테스트 스위트를 그대로 돌려보는 것만으로도 호환성 확인이 거의 됩니다. 라이브러리 자체가 워낙 넓게 깔려 있는 만큼, 팀 안에서 "일단 브랜치 하나 파서 돌려보자"는 결정이 가장 빠른 판단 방법입니다.
솔직히 말하면, 처음 변경 목록을 쭉 읽었을 때 "이번엔 진짜 큰 거 왔네"라는 생각이 먼저 들었습니다. ONNX 지원율 수치도 수치지만, 토크나이저와 KV캐시까지 라이브러리 안으로 끌어들인 결정이 특히 인상적이었거든요. 지금까지 OpenCV는 "전처리·후처리는 내가 맡을게, 모델 추론은 네가 알아서 해"라는 역할 분담이 암묵적으로 있었는데, 그 경계를 스스로 허문 셈입니다.
그렇다고 완성형이라고 부르기엔 아직 솔직하지 못한 부분이 남아 있습니다. 새 DNN 엔진의 GPU 가속은 아직 미지원 상태이고 (로드맵에는 있지만 5.0 릴리스 시점 기준으로는 CPU 전용입니다), Camera I/O API 개편도 진행 중인 것으로 문서에 명시되어 있습니다. GPU 파이프라인에 크게 의존하는 프로젝트라면 이 점이 꽤 결정적인 제약으로 느껴질 수 있습니다. 저라면 그 경우엔 조금 더 기다릴 것 같습니다.
💡 핵심: OpenCV 5는 단순 기능 추가가 아니라 역할 경계 자체를 다시 그은 릴리스입니다.
ENGINE_AUTO하나로 세 엔진을 추상화한 구조는 하드웨어 파편화 시대에 실용적인 선택이고, LaMa·ALIKED·LightGlue의 표준 API 편입은 "이 라이브러리 하나로 웬만한 파이프라인은 다 된다"는 방향성을 분명히 합니다.
전체 그림을 놓고 보면, 이번 업데이트는 단순한 기능 추가라기보다 OpenCV가 앞으로 10년을 어떻게 설계할지 보여주는 신호에 가깝습니다. ENGINE_AUTO 하나로 세 엔진을 추상화한 구조는 하드웨어 파편화가 점점 심해지는 환경에서 상당히 실용적인 선택이었고, LaMa·ALIKED·LightGlue 같은 모델들이 표준 API로 묶인 것도 "이 라이브러리 하나로 웬만한 파이프라인은 다 된다"는 방향성을 분명히 하고 있습니다. 86,000개 GitHub 스타, 하루 백만 건 이상의 설치 수를 가진 라이브러리가 이 방향으로 무게중심을 옮겼다는 건, 커뮤니티 전체의 관성도 함께 움직인다는 의미이기도 합니다.
저는 일단 사이드 브랜치에서 돌려보고 있는데, 아직 GPU 이슈가 해소되는 다음 마이너 릴리스가 더 기다려집니다.
Q. OpenCV 5에서 ONNX 지원율이 크게 오른 이유가 뭔가요?
A. 기존 레이어 단위 실행 방식을 그래프 기반 실행 엔진으로 교체했기 때문입니다. 모델 전체를 계산 그래프로 파싱해 동적 shape와 제어 흐름(If·Loop)을 런타임에 처리할 수 있게 됐고, 덕분에 지원율이 22%에서 80%까지 올랐습니다.
Q. OpenCV 5의 새 DNN 엔진에서 GPU 가속은 바로 쓸 수 있나요?
A. 5.0 릴리스 기준으로는 아직 CPU 전용입니다. GPU 가속은 로드맵에는 포함되어 있지만 이번 버전에서는 지원되지 않아요. GPU 파이프라인에 크게 의존하는 프로젝트라면 다음 마이너 릴리스를 기다리는 편이 나을 수 있습니다.
Q. OpenCV 5에서 LLM·VLM을 직접 실행할 수 있다는 게 어떤 의미인가요?
A. 기존 OpenCV는 전처리·후처리를 담당하고 모델 추론은 외부 프레임워크에 맡기는 역할 분담이 암묵적으로 있었는데, 이번 릴리스에서 그 경계를 스스로 허물었습니다. LaMa·ALIKED·LightGlue 같은 모델이 표준 API로 편입된 것도 같은 방향성으로, OpenCV 하나로 웬만한 파이프라인을 구성할 수 있는 기반이 마련된 겁니다.